
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- SQL 연산자
- 관계형데이터베이스
- 스프링
- Hooks
- Eclipse
- Flexbox Froggy
- 타입
- SQL 문제
- 이클립스
- 자바스프링
- ubuntu
- 리액트
- java spring
- 객체지향프로그래밍
- node.js
- 노마드코더
- java설치
- 자바 스프링
- spring
- Flex Box 기본
- REACT
- HTML5
- SQL 명령어
- SQL
- numpy
- 오산대맛집
- 플랙스박스기본
- spring 환경설정
- 람다식
- 환경설정
- Today
- Total
이것저것
[SQL] 명령어 정리 본문
SQL Developer에서 작성하였다.
ctrl+shift+d를 누르면 쉽게 복사할 수 있다.
추가 내용 : F5 대신에 ctrl + Enter로 출력하게 되면 표형식으로 출력 가능하다.
-- 주석처리입니다 --
/** 주석처리입니다. **/
-- 실행 단축키는 F5입니다 --
-- 대소문자는 구분되지 않지만 대분자로 적는게 좋다. --
-- 테이블 만들기 --
CREATE TABLE tab01(
ID NUMBER,
NAME VARCHAR2(20)
);
/** f5를 눌러 테이블 생성
바로 f5를 누르면 오류 메세지가 뜨게된다.
이미 생성된 테이블이기 때문이다.
새로운 테이블을 만들어 주기위해서는 tab01소스를 주석처리해주거나 수정해서 생성해야한다.**/char와 varchar2의 차이는 지금은 없다.
하지만 varchar2가 가장 최신 용어이기 때문에 권장사항이다.
테이블 목록보기
-- *은 아스트릭 혹은 모든것 --
SELECT * FROM TAB;
-- 현재 존재하는 테이블 목록을 보여준다. --
테이블 삭제 명령어
drop table 테이블명
DROP TABLE TAB02;
-- 테이블 삭제 --
쓰레기통 확인과 쓰레기통 비우기
-- 쓰레기통에 삭제된 데이터 확인 --
SHOW recyclebin;
-- 쓰레기통을 비우는 명령어 --
PURGE RECYCLEBIN;
commit은 항상 모든 수정이나 추가, 삭제 작업이 끝나고 해주는 것이 좋다.
-- 추가나 수정을 하고서 저장이 안될수도 있으므로 commit은 항상해주는게 좋다. --
--commit을 안하고 저장이안된상태에서 developer를 꺼버리면 날아갈수도 있다.--
commit;
table을 생성할 때 이전에 만들어 놓은 것이 있을 수도 있으니 삭제를 해서 확인해주고 테이블을 생성해주는 게 좋다.
--생성할때 있으면 지우고 생성하기 위해서 DROP TABLE을 같이 적어준다. --
DROP TABLE TAB01;
CREATE TABLE tab01(
ID NUMBER,
NAME VARCHAR2(20)
);
테이블의 이름을 수정하고 싶을 때 사용한다.
rename 원래 이름 to 바꿀 이름
rename tab101 to tab202;
description의 약자로 desc를 쓴다.
table의 속성들을 볼 때 쓴다.
desc tab202;
속성 값을 attribute라 하고 행, 필드라고 한다.
속성 안에 들어간 값들을 tuple, 레코드라고 한다.
속성 값을 추가해줄 때는 ALERT를 쓴다.
ALTER TABLE tab202 ADD(
ADDRESS VARCHAR2(20),
PASS VARCHAR2(10)
);테이블 순서는 복사하는 방법으로 고칠 수는 있지만 그냥 바꿀 수 있다 정도만 알고 있으면 된다.(?)
속성 값을 지우는 명령어
ALTER TABLE 테이블명 DROP COLUMN 속성명
ALTER TABLE TAB202 DROP COLUMN PASS;
속성에 값을 넣어주는 명령어이다.
INSERT INTO는 2가지 방법으로 나눠진다.
첫 번째는 필드를 적지 않아도 전부 적었다는 가정하에 만드는 것이기 때문에 묵시적 방법이라고 한다.
INSERT INTO TAB01 VALUES(1, 'ADSF');
INSERT INTO TAB01 VALUES(2, '호랑이');
INSERT INTO TAB01 VALUES(3, 'Lion');두 번째는 내가 할 필드를 따로 적어주는 것이기 때문에 암시적 방법이라고 한다.
INSERT INTO TAB01 (ID, NAME) VALUES(1, '호랑이');필드에 초기값을 넣을 때 number로 된 곳에는 산술식을 추가할 수 있다.
INSERT INTO TAB01 VALUES(10+10, '사자', 360*1.2);굳이 연산식을 쓰는 것은 나중에 코드를 짤 때 변수로 추가할 때 유용하게 쓰일 수 있다.
ex) 직원들의 급여를 20프로 인상할 때
&a, &b, &c를 사용하면 실행했을 때 입력값을 넣을 수 있다.
하지만 &b는 varchar2이기 때문에 '입력값'으로 넣어야지 오류가 뜨지 않는다.
INSERT INTO TAB01 VALUES(&a, &b, &c);
INSERT INTO TAB01 VALUES(&a, '&b', &c);
/** 위에서 b를 입력할때 입력창에 ''을 같이 입력해줘야하지만
아래처럼 '&b'라고 넣어두면 ''을 따로 붙히지 않아도된다.**/
선택된 테이블의 속성을 보기 위한 방법으로 첫 번째는 모든 속성을 보는 것이다.
두 번째는 속성 값을 선택해서 출력해준다.
SELECT * FROM TAB01;
SELECT ID, SALARY FROM TAB01;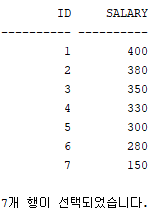
TAB01에 들어간 속성 값들의 개수를 카운트해준다.
SELECT COUNT (*) FROM TAB01;
속성 값에 별칭을 붙여주기 위해서 사용한다. 실제로 많이 쓰인다.
SELECT ID AS 아이디, NAME AS 이름, SALARY AS 급여 FROM TAB01;
/** AS를 생략할 수 있다.
하지만 나중에 보면 가독성이 떨어지고 무슨 코든지 못알아 볼수도있다. **/
SELECT ID 아이디, NAME 이름, SALARY 급여 FROM TAB01;
--스페이스를 사용하고 싶을때 ""을 사용한다.
SELECT ID 아이디, NAME "이 름", SALARY 급여 FROM TAB01;
칸을 두지 않고 하나로 합쳐져서 나타내고 싶을 경우
SELECT (NAME || SALARY) AS "합 친 필 드" FROM TAB01;
뒤에 여러 가지를 추가할 수 있다.
SELECT (NAME || SALARY) AS "합 친 필 드", ID, NAME, SALARY, ID FROM TAB01;TAB01에서 이름이 겹치는 부분들을 빼고 표현해준다.
첫 번째는 겹치는 이름들을 하나로 표현해주었고
두 번째는 겹치는 이름들을 제외하고 나온 것의 개수를 표현하였다.
--겹치는 이름들을 하나로 표시하고 출력해준다.
SELECT DISTINCT (NAME) FROM TAB01;
--겹치는 부분을 제외하고 count해준다.
SELECT COUNT (DISTINCT NAME) FROM TAB01;

asc는 순차라는 뜻을 가지고 있다. 순차적으로 정렬해준다.
SELECT * FROM tab01 order by country asc;
-- asc는 생략할 수 있다. default값은 asc이다.
SELECT * FROM tab01 order by country;
--desc는 역으로 정렬해준다.
SELECT * FROM tab01 order by country desc;
--order by 뒤에 1,2,3과 같은 숫자를 넣어주게되면 1은 id 2는 name 3은 country 값으로 정렬을 해준다.
SELECT * FROM tab01 order by country 1;
SELECT * FROM tab01 order by country 2;
SELECT * FROM tab01 order by country 3;1차, 2차 정렬을 해줄 때 사용한다.
첫 번째 값을 1차로 정렬해주고 두 번째 적은 값을 2차로 정렬해준다.
--1차정렬로 급여를하고 2차정렬로 id값을 정렬한다.
SELECT * FROM TAB01 order by salary, id;
-- 급여는 역순, id는 순차정렬을 해준다.
SELECT * FROM TAB01 order by salary desc, id;
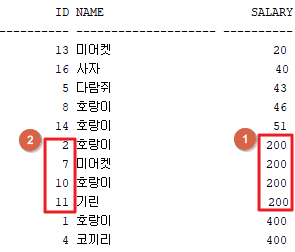
일반적으로 tab01 다음으로 엔터를 치고 코드를 입력을 한다.
SELECT * FROM tab01
order by name;
12명의 학생 이름, 학과(3종류: 컴공, 중국어, 요리) 점수 학과 순서대로 정렬 점수 높은 순으로 출력
평균을 구할 때 소수점까지 나오는 부분을 깔끔히 하기 위해서 trunc를 사용하면 소수점 자릿수를 생략할 수 있다.
SELECT name as "이 름", depart "학 과", lan, math, eng, trunc((lan+math+eng)/3) 총점
FROM tab01 order by 총점;
where는 조건문이다.(if문과 같다)
salary가 120보다 큰 것만 출력하고 name순으로 정렬한다.
SELECT * FROM tab02
where salary>120
order by namesalary가 급여라고 하면 연봉이 2000 이상인 사람을 출력하고 해당 값을 카운트해주는 코드이다.
select count(*) FROM (
select * FROM tab02
where (salary*12)>2000
);
--아래의 값도 출력된다.
select count(*) FROM tab02
where (salary*12)>2000;
명령어의 순서이다.
select
-- 여기서 as를 이용한 별칭을 만든다면 group by 뒤부터 사용 할 수 있다.
-- 그룹에서 묶인 것으로 쓸수 있고 조건문에서는 쓸 수 없다.
from
where
group by
having
order by
--그래서 아래문장은 오류가 난다.
select salary*12 as tiger From tab02 where tiger>2000
'Database' 카테고리의 다른 글
| [SQL]서브쿼리문 (0) | 2020.06.03 |
|---|---|
| [SQL]JOIN (0) | 2020.06.02 |
| [SQL] UNION, 연산자, ROLLUP, GROUPING (0) | 2020.06.01 |
| [SQL]데이터 조회, 연산자 (0) | 2020.05.29 |
| [SQL Developer]SQL Developer 설치 (0) | 2020.05.27 |


